

什么是Hadoop?

hadoop中有3个核心组件 分布式文件系统: —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架: —— 实现在很多机器上分布式并行运算 分布式资源调度平台: —— 帮用户调度大量的mapreduce程序,并合理分配运算资源
专业术语
- online Transaction Processing 联机事务处理
- online Analytical Processing 联机实时分析
- Hybrid Transaction & Analytical Processing 混合事务和分析处理
- Massively Parallel Processing 大规模并行处理
- 在基于列式存储的数据库中,数据是按照列为基础逻辑存储单元进行存储的,一列中的数据在存储介质中以连续存储形式存在
数仓建模以及分层
- ODS
ODS是数据接入层,所有进入数据的数据首先会接入ODS层。一般来说ODS层的数据是多复杂多样的。从数据粒度上看ODS层是粒度最细的数据层。
- DIM
维表层 公共维度汇总层(DIM)主要由维度表(维表)构成。维度是逻辑概念,是衡量和观察业务的角度。维表是根据维度及其属性将数据平台上构建的物理化的表,采用宽表设计的原则。因此,公共维度汇总层(DIM)首先需要定义维度。
- DWD
为数据仓库层,数据明细层的数据应是经过ODS清洗,转后的一致的、准确的、干净的数据。DWD层数据粒度通常和ODS的粒度相同,不同的是该层的数据质量更高,字段更全面等。在数据明细层会保存BI系统中所有的历史数据,例如保存近10年来的数据。例如 对ODS层数据进行清洗(去除空值,脏数据,超过极限范围的数据)、维度退化脱敏等
- DWS
数据集市层,该层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。例如 以DWD为基础,按天进行轻度汇总。
- DWT
数据应用层,它是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。从数据粒度来说是高度汇总的数据。其汇总的目标主要是按照应用需求进行的。例如 以DWS为基础,按主题进行汇总。
- ADS
ADS层:为各种报表提供数据。
其他
- 是有向无环图(Directed Acyclic Graph)
- 星型模型
- 雪花模型
- Hbase 基于hdsf
- TiDB
- ClickHouse
- InfluxDB
- GraphQL
- Elasticsearch
Hadoop database 的简称,也就是基于,是一种OLTP 数据库nosql ,主要适用于海量明细数据(十亿、百亿)的随机,如日志明细、交易清单、轨迹行为等
开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理HTAP
时序数据库
本质是一个OLTP 系统的列式数据库,主要做即时查询,大宽表,单表查询速度极佳,join表现差,明细数据查询
是一种针对 Graph(图状数据)进行查询特别有优势的 Query Language(查询语言),所以叫做 GraphQL
是一个分布式的免费开源搜索和分析引擎
开源MPP分析型数据库产品 ,灵活的多维度查询,join表现比Clickhouse好,明细数据查询,数量级支持TP-PB,需要注意的是Doris是mysql语法
- sqoop
- canal
- DataX
- maxwell
- Kettle
- StreamSets
- MapReduce
- YARN
- hive
- Spark
是 Hadoop 2.0 版本以后的资源管理器,即 MapReduce 2.0,相比于 1.0 版本,架构中的各个模块分工明确,在性能和稳定性上都有所提升。YARN 负责整个集群资源的管理和调度,也就是说所有的 MapReduce 都需要通过它来进行调度,支持多种计算框架。
是,能帮助熟悉SQL的人运行MapReduce任务,做一些数据清洗(ETL)、报表、数据分析,时间消耗长,适合
的出现就弥补了MapReduce的不足。 spark是一种基于内存的快速、通用、可扩展的大数据计算引擎,应用于 批处理 用于ETL(抽取、转换、加载)。
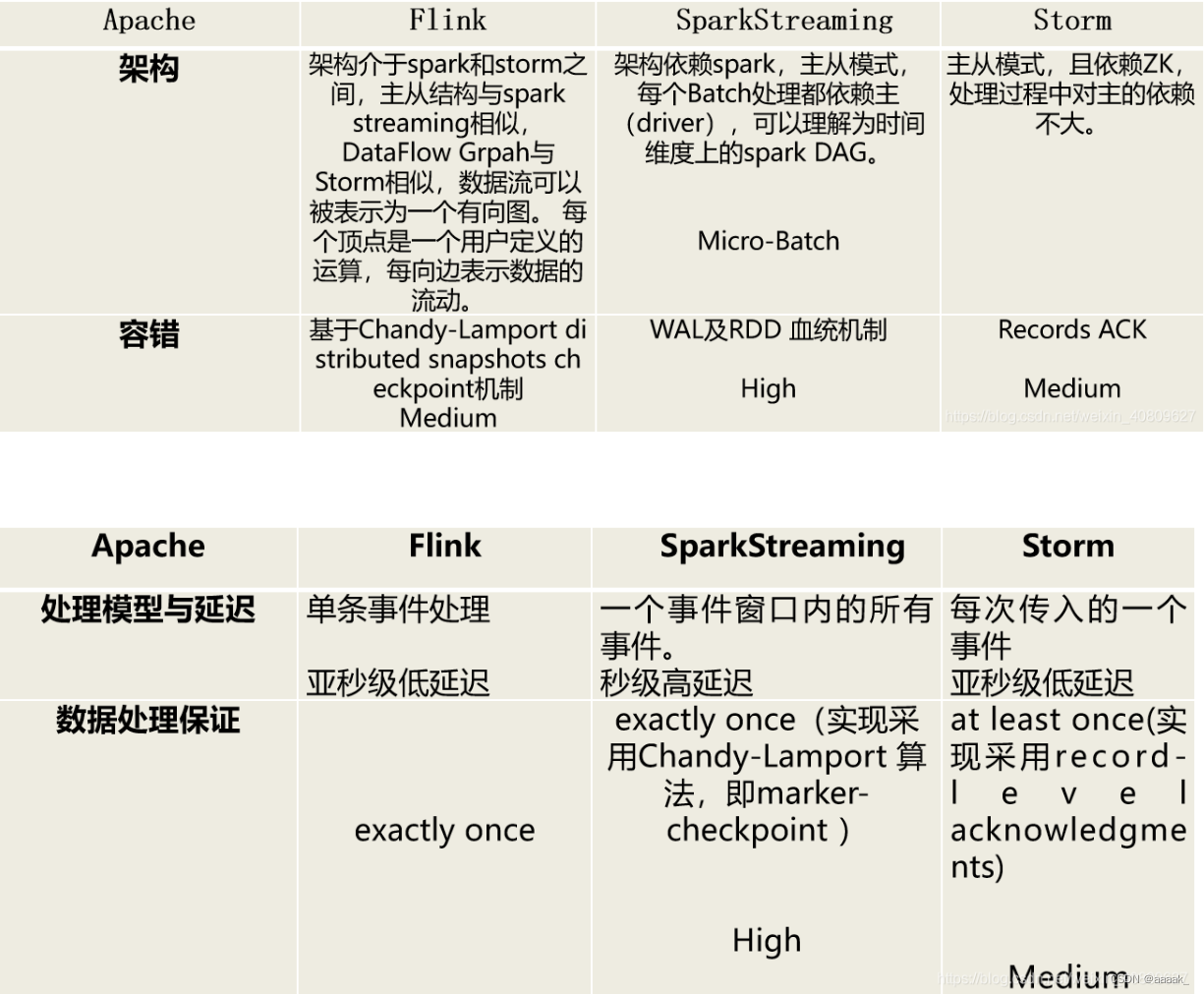
- storm
- spark stream
- hdsf
- Apache Ozone
- s3
- oss
- Ceph
- GlusterFS
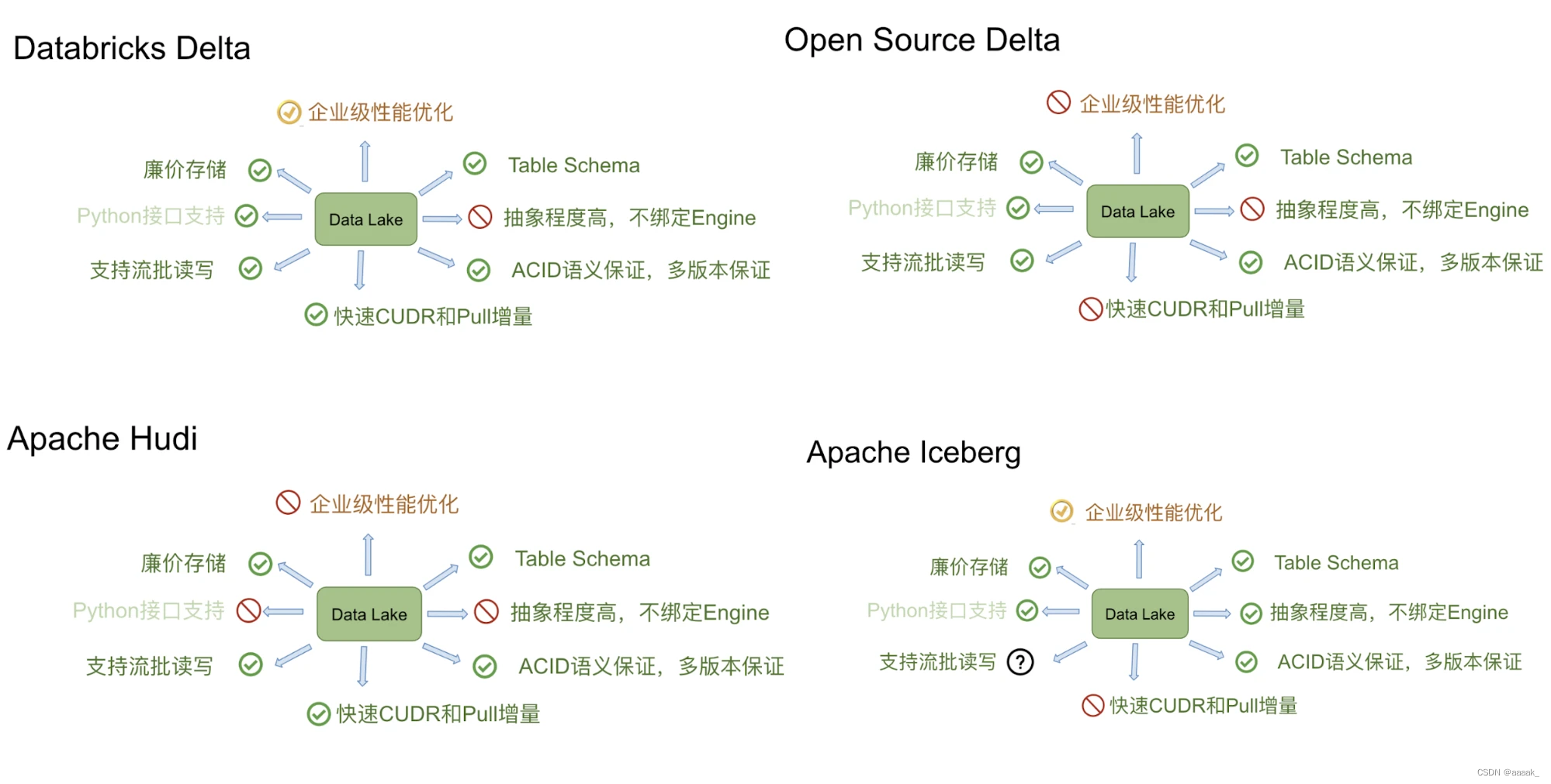
- Apache Hudi
- Apache Iceberg
- Delta Lake
- Airflow
- Oozie
是一个可编程的工作流调度、监控平台。可分布式部署调用,基于DAG(本身没有队列功能,需要使用第三方组件,比如redis、rabbitMQ),airflow用python进行编程 开发,可以进行丰富的任务处理,包括bash命令的执行、python代码调用、发送邮件、发送Http请求等。 airflow websever -D启动airflow的web界面
是一个工作流监控、调度工具。可以部署分布式,通过在job文件中以properties格式配置任务并打包成zip包即可进行调度。azkaban内部架构包括三部分 excutorServer、webServer、mysql,分别负责任务的执行、web界面的显示、调度信息的存储。 azkaban是一个轻量级的调度器。
是一个基于hadoop的分布式的工作流调度框架,oozie通过在xml文件中配置任务来进行调度,执行调度时会启动MR任务,依赖于hadoop平台,是一个重量级框架。
是一个分布式、易扩展的可视化DAG工作流任务调度平台,解决数据处理流程中错综复杂的依赖关系 所有流定时操作都是可视化的,通过拖拽来绘制DAG,配置数据源及资源,同时对于第三方系统,提供api方式的操作
- Ambari
- CDH (Cloudera版本)
- HDP (Hortonworks版)
- CDP (Cloudera和Hortonworks合并后 收费)
- USDP (国人ucloud版)
- CRH (基于 Apache Ambari + Apache BigTop)
- TDH (星环 收费闭源)
Ambari是Apache软件基金顶级项目,它是一个基于web的工具,用于安装、配置、管理和监视Apache Hadoop集群,支持Hadoop HDFS,、Hadoop MapReduce、Hive、HCatalog,、Hbase、ZooKeeper、Oozie、Pig和Sqoop。Ambari同样还提供了集群状况仪表盘,比如heatmaps和查看MapReduce、Pig、Hive应用程序的能力,以友好的用户界面对它们的性能特性进行诊断。
CDH 是Hadoop众多分支中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop构建
Hortonworks 主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,HDP除了常见的项目外还包含了Ambari,一款开源的安装和管理系统。HCatalog,一个元数据管理系统。
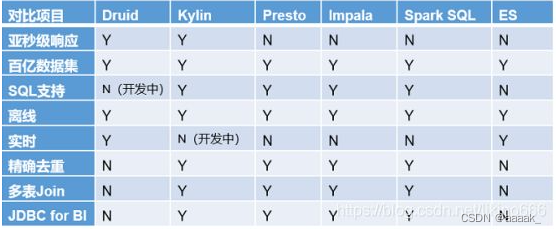
即席查询是用户根据自己的需求,灵活的选择查询条件,系统根据用户的选择生成相应的统计报表。普通查应用查询是定制开发的,即席查询是用户自定义查询条件
理解:快速的执行自定义SQL(可能无法提前运算和预测)
-
:是一个实时处理时序数据的OLAP数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。
-
:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
-
:它没有使用Mapreduce,大部分场景下比HIVE快一个数量级,其中的关键是所有的处理都在内存中完成。
-
:基于内存计算,速度快,支持的数据源没有Presto多。
